

pythonのlistの繰り返し処理をする際に使える手軽な高速化方法を紹介します
この記事を読むとわかること・・
- listの処理を高速化する方法
- 高速化する際のポイント
基本的な繰り返し処理(for文)
まずは基本的なforを使います
今回は準備として
100万人分のテストの得点が入ったlistを作ります
# coding: UTF-8
# 必要なライブラリのインポート
import ramdom
# データの作成(100万人のテストの点数が入ったリストを作成)
test_score_list = [random.randint(0, 100) for i in range(1000000)]
print(test_score_list)
# [95, 87, 31, 99, 75, 35, 38, 36, 91, 31, 23, 36, ・・・・]
print(len(test_score_list))
# 1000000速度を比較するために実装する処理はこんな感じ

すべて同様の処理をして速度を比較していきます
計測方法は『%%timeit』により計測します
%%timeitの使い方が知りたい方はこちらを参考にしてください
# forを使った処理
judge_list = [] # True, Falseを格納するリストを作成
for test_score in test_score_list:
if test_score >= 50: # 50点以上の場合
judge_list.append(True)
else: # 50点未満の場合
judge_list.append(False)
print(judge_list)
# [True, True, False, True, True, False・・・]
print(len(judge_list)) # 50点以上の人の合計
# 504953
# 計測時間
78.6 ms ± 2.01 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)内包表記による処理1
次は高速化では定番の内包表記による処理を試してみます
# 内包表記を使った処理
# True, Falseを格納するリストを作成
over_fifty_list = [True if test_score >= 50 else False for test_score in test_score_list]
print(judge_list)
# [True, True, False, True, True, False・・・]
print(len(judge_list)) # 50点以上の人の合計
# 504953
# 計測時間
49.3 ms ± 494 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)内包表記による処理2(簡略化ver.)
先ほどの処理を実はもう少し簡略することができます
# 内包表記(簡略化ver.)を使った処理
# True, Falseを格納するリストを作成
over_fifty_list = [test_score >= 50 for test_score in test_score_list]
print(judge_list)
# [True, True, False, True, True, False・・・]
print(len(judge_list)) # 50点以上の人の合計
# 504953
# 計測時間
41.6 ms ± 286 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)内包表記で条件式を適用するとbool型(True, False)を要素とするリストを作成することができます
ちなみに、bool型のTrueは1 , Falseは0として扱われます
ジェネレーター式
この場合はTrue, Falseの格納されたリストを作成することはできませんが
50点以上を取った人の数を知ることができます
# ジェネレーター式を使った処理
# True, Falseを格納するリストを作成
judge_generator = (test_score >= 50 for test_score in test_score_list)
print(judge_generator)
# <generator object <genexpr> at 0x10c849ba0>
print(len(judge_generator)) # 50点以上の人の合計
# TypeError: object of type 'generator' has no len()
print(sum(judge_generator))
# 504953
# 計測時間
320 ns ± 10.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)ジェネレーター式はreturnの代わりにyieldなどを内部的に使用しているため・・・(略)
要は必要なときに必要最低限の処理をするためメモリ消費を抑えてくれます
ユニバーサル関数(ufunc)
ユニバーサル関数(ufunc)とは・・・
Numpyの配列(ndarray)を要素ごとに処理をして配列(ndarray)で結果を返す関数
Numpyライブラリで提供されている関数ですが、
これは自作関数もユニバーサル関数として使用することができます
# ユニバーサル関数を使った処理
# 自作関数を作成
def judge_func(test_score):
"""
50点以上か判定する関数
"""
if test_score >= 50:
return True
else:
return False
# 自作関数をユニバーサル化する
judge_func_uni = np.frompyfunc(judge_func, 1, 1) # ユニバーサル関数化
# True, Falseを格納するリストを作成
judge_list = [judge_func_uni(test_score) for test_score in test_score_list]
print(judge_list)
# [True, True, False, True, True, False・・・]
print(len(judge_list)) # 50点以上の人の合計
# 504953
# 計測時間
1.32 s ± 11.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)map関数による処理
最後はmap関数による処理です
# map関数を使った処理
# True, Falseを格納するリストを作成
judge_list = list(map(lambda x: True if x >= 50 else False, test_score_list))
print(judge_list)
# [True, True, False, True, True, False・・・]
print(len(judge_list)) # 50点以上の人の合計
# 504953
# 計測時間
81.3 ms ± 1.4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)map関数はlambdaと組み合わせて使用することが多いです
pandasのdataframeでもmap関数を使用することが結構あります
結果まとめ
今回の結果を一覧にしてみます

ユニバーサル関数は遅いので、それを除いた方法をグラフにすると・・・
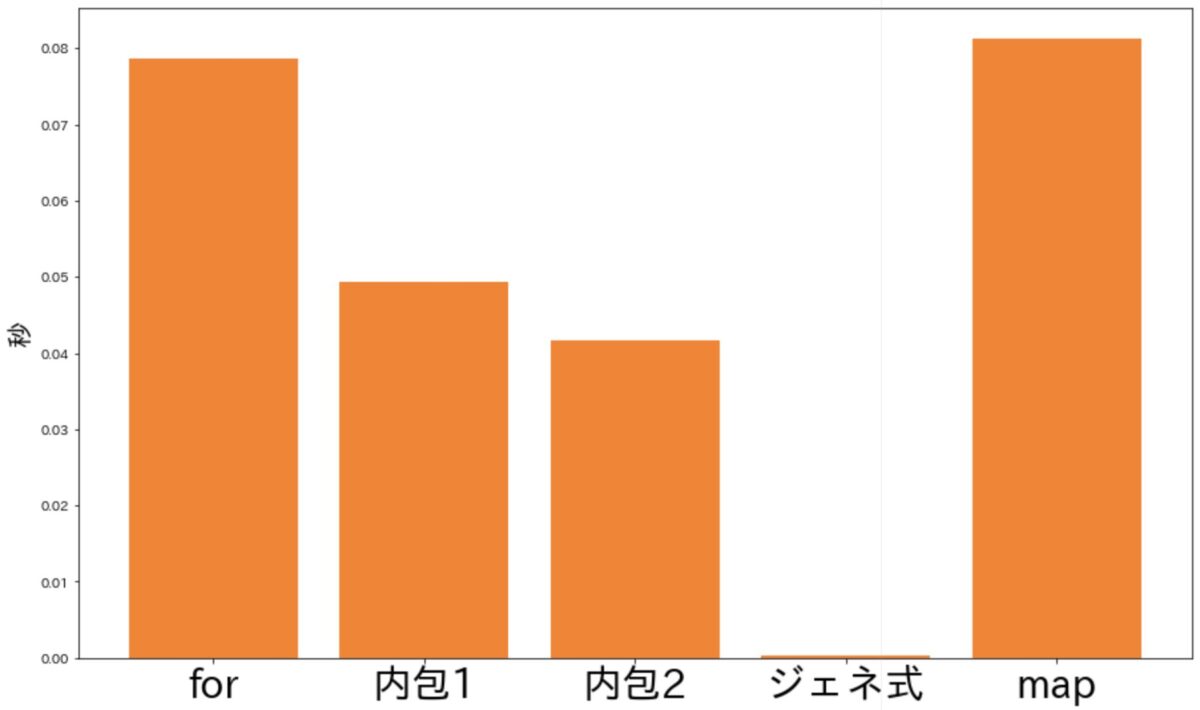
ジェネレーター式がダントツで早い結果となりました
ただ全ての場合においてジェネレーター式が早いという結論ではないので
注意してください
やりたいことによって最適な方法は変わるので
まずは引き出しを増やすことが大切です
一緒に高速化の引き出しを増やせるように頑張っていきましょう
