

今回は、NumbaによるJIT(Just-In-Time)コンパイルを
使用して処理速度を劇的にupする方法を解説します
この記事を読むべき方・・・
- Pythonを使用しているエンジニアやデータサイエンティスト
- Numpyを使用しているが、さらに高速化したいと考えているプログラマー
- Numbaを初めて知る、または使用経験が浅い開発者
Numbaとは?
Numbaとは
Pythonの数値計算ライブラリである
コードをコンパイルして高速化するためのツールです
NumbaはJITコンパイルを活用し
処理を高速化しています
pythonのインタプリタ型言語の特徴を生かしつつ
一部を機械語に変換して実行することで
高速な処理を実現しています
コンパイル言語とインタープリタ言語の違い
- コンパイル言語とインタープリタ言語の違いについてはこちらをクリック
コンパイル言語
- 事前コンパイル:コード全体を機械語に変換(コンパイル)してから実行
- 実行速度が速い:機械語で実行されるため、実行時の処理が高速
- データ型の統一:データ型などを統一する必要がある
- コンパイル言語:C言語、C++、Java(JVMにバイトコードとしてコンパイル)
インタープリタ言語
- コンパイル不要:コードを一行ずつ逐次実行
- 実行速度が遅い:コードを解釈しながらのため、コンパイル言語に比べて速度が遅い
- データ型は自由:データ型が違っていても比較的エラーは少ない(動的解釈)
- インタプリター言語:Python、JavaScript、Ruby
コンパイルとは:人間が書いたプログラムを機械語に変換することコンパイル言語:高速でエラーが事前に検出できる
インタープリタ言語:柔軟性が高く、デバッグがしやすい
という特徴があります
NumpyとNumbaの違い
NumbaとNumpyの違いについて
解説しておきます
Numpy
Numba
一部の操作(オブジェクト,例外処理etc.)はできない可能性があるよ
Numbaのコードの基本的な書き方
Numbaのコードの書き方は以下のとおりです
from numba import jit
@jit
def my_function(x):
# ここでxについての処理を記述
return x
特徴的な使い方としては
関数の頭に@jitデコレータを付けます
jitにはさまざまなオプションがあるので
気になる方は参考にしてみてください
jitオプション一覧
- jitオプション一覧はこちらをクリック
1. nopython
- 説明: 全コードをコンパイルして処理を高速化(Pythonの通常の動きをやめて、超速くする)
- 使い方:
@jit(nopython=True) def my_function(x): return x2. parallel
- 説明: 並列処理を行い、処理を高速化(同時並行で処理をして、速くする)
- 使い方:
@jit(parallel=True) def my_function(x): return x3. cache
- 説明: コンパイル結果を保存し、再利用で時間を節約(一度作った結果を保存しておいて、次回から速くする)
- 使い方:
@jit(cache=True) def my_function(x): return x4. error_model
- 説明: 浮動小数点数のエラー処理方法を指定(PythonかNumpyの方式を選べる)
- 使い方:
@jit(error_model="numpy") def my_function(x): return x5. fastmath
- 説明: 数学演算の最適化で処理を高速化(計算を少し速くするために、ほんの少しだけ正確さを減らす)
- 使い方:
@jit(fastmath=True) def my_function(x): return x6. forceobj
- 説明: Pythonの通常のオブジェクトモードを強制使用(普通のPythonの動きで、全部使えるようにする)
- 使い方:
@jit(forceobj=True) def my_function(x): return x7. nogil
- 説明: GILを解放し、並列処理を可能に(一度に複数のことをできるようにする)
- 使い方:
@jit(nogil=True) def my_function(x): return x8. boundscheck
- 説明: 配列やリストの範囲外アクセスをチェック(リストの範囲を間違えないようにチェックする)
- 使い方:
@jit(boundscheck=True) def my_function(x): return x9. inline
- 説明: 関数呼び出しをインライン化して速度向上(関数を展開して速くする)
- 使い方:
@jit(inline="always") def my_function(x): return x10. locals
- 説明: 特定の変数に型指定を行い、処理を効率化(変数の種類を決めて速くする)
- 使い方:
@jit(locals={'x': int32, 'y': float64}) def my_function(x, y): return x + yこれらのオプションは、関数をより速く
効率的に動かすために使われますおへんじ それぞれのオプションの意味を理解して適切に使ってねー
コツ1.演算の高速化
ここから実際にNumbaを使った
演算の高速化方法を解説します
NumpyとNumbaで比較して
処理速度の違いを見てみましょう
今回の例では、100万個の要素を持つ配列に対して
各要素の2乗を計算する処理を行ってみます
Numpyによる実装
import numpy as np
import time
# 配列の作成: 0から999999までの整数を持つNumpy配列を作成
arr = np.arange(1000000)
# arr中身
array([ 0, 1, 2, ..., 999997, 999998, 999999])
# 演算開始
%%timeit
result = arr ** 2 # 配列の各要素を2乗
# result中身
array([ 0, 1, 4, ..., 999994000009, 999996000004, 999998000001])
# 処理時間
1.23 ms ± 148 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Numbaによる実装
from numba import jit # Numbaのjitデコレータをインポート
import numpy as np
import time
# 配列の作成: 0から999999までの整数を持つNumpy配列を作成
arr = np.arange(1000000)
# arr中身
array([ 0, 1, 2, ..., 999997, 999998, 999999])
# JITコンパイルを適用した関数を定義
@jit(nopython=True)
def square_array(arr):
result = np.empty_like(arr) # 入力配列と同じサイズの空の配列を作成
for i in range(arr.size): # 各要素に対して処理を行うループ
result[i] = arr[i] ** 2 # 各要素を2乗して結果を格納
return result # 結果の配列を返す
# 演算開始
%%timeit
result = square_array(arr) # JITコンパイルされた関数を実行
# result中身
array([ 0, 1, 4, ..., 999994000009, 999996000004, 999998000001])
# 処理時間
1.1 ms ± 73.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
処理速度は以下のとおりでした
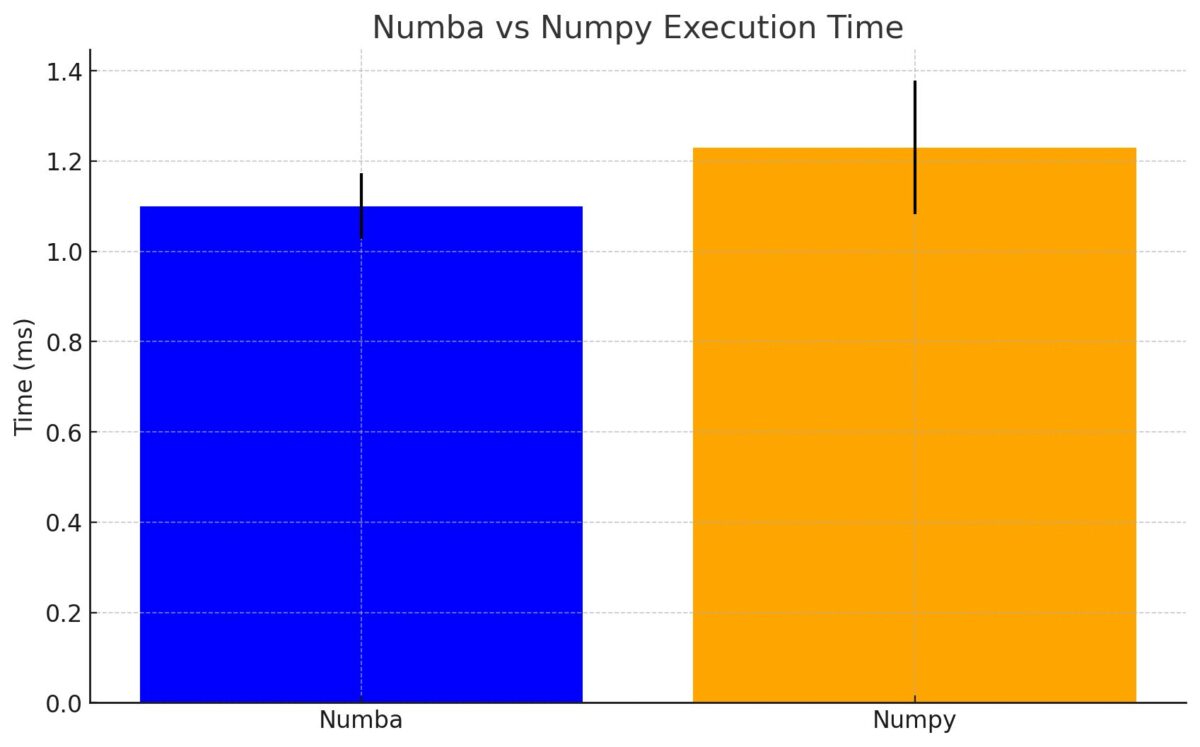
Numbaの方がNumpyよりも
若干速い結果となりました
こういった処理はnumpyも高速に処理できるため
処理速度に大きな差はない結果となりました
@jit(nopython=True) にすることで
Pythonの遅いインタプリタを回避し
完全に機械語で動作させます
高速化の理由・・・
Pythonのforなどの標準ループは遅いですが
Numbaではこのループ処理がJITコンパイルによって
機械語に変換されるため、C言語に匹敵する高速な処理が可能です
コツ2.カスタムなベクトル・行列演算の高速化
Numbaは、特にカスタムなベクトルや
行列演算でその威力を発揮します
今回の例では1000×1000のランダムな行列を
作成して行列の数値に応じた行列演算をしてみます
通常の行列演算はNumpyで十分に高速ですが
要素ごとに異なる処理が必要な場合や
条件付きで演算を行うような複雑なケースでは
Numpyの効率が低下することがあります
Numpyによる実装
import numpy as np
import time
# 1000x1000のランダム行列を作成
A = np.random.rand(1000, 1000)
# Numpyで条件付き演算を実行
%%timeit
B = np.where(A > 0.5, A * 2, A / 2) # 要素が0.5より大きければ2倍、小さければ半分に
# 処理時間
7.11 ms ± 818 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Numbaによる実装
from numba import jit
import numpy as np
import time
# 1000x1000のランダム行列を作成
A = np.random.rand(1000, 1000)
# JITコンパイルを適用した条件付き演算関数を定義
@jit(nopython=True)
def custom_operation(A):
n = A.shape[0]
B = np.empty_like(A) # 結果を格納する配列を初期化
for i in range(n):
for j in range(n):
if A[i, j] > 0.5:
B[i, j] = A[i, j] * 2 # 条件を満たす場合、要素を2倍
else:
B[i, j] = A[i, j] / 2 # 条件を満たさない場合、要素を半分に
return B
# Numbaで条件付き演算を実行
%%timeit
B = custom_operation(A) # JITコンパイルされた関数を実行
# 処理時間
1.48 ms ± 65.3 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
処理速度は以下のとおりでした
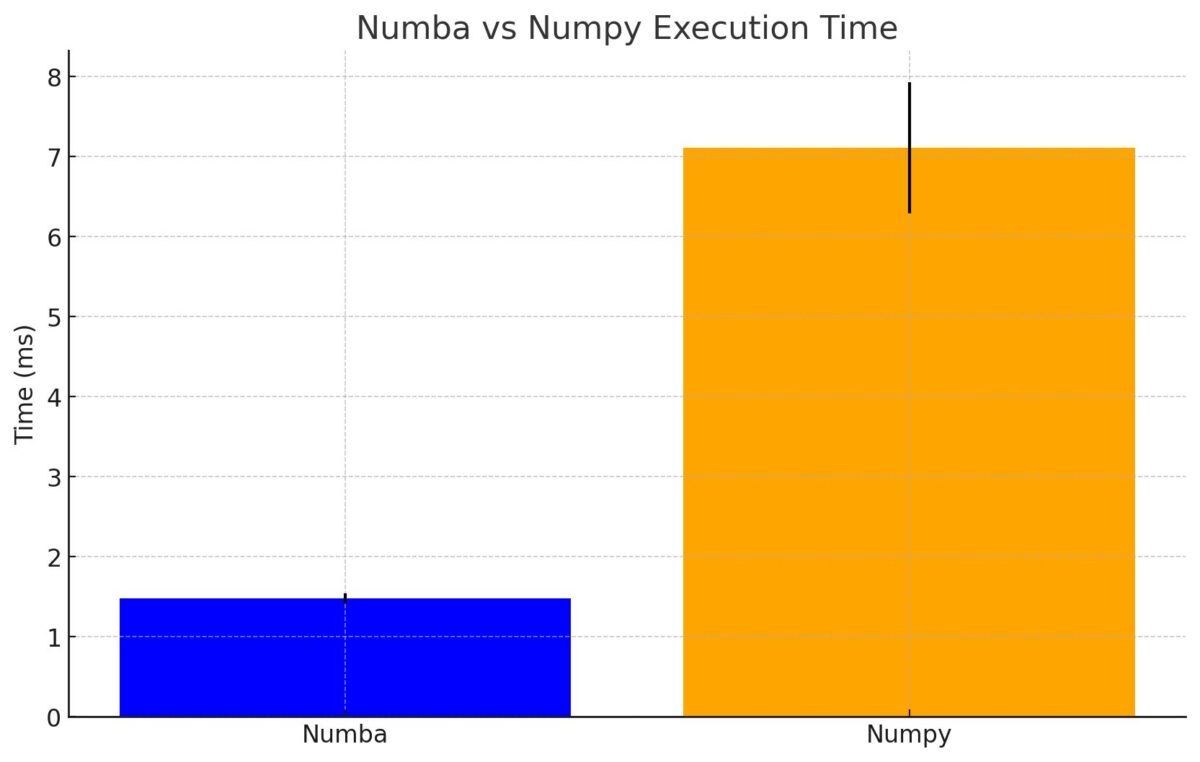
Numbaの方が3倍程度速い結果となりました
高速化の理由・・・
コツ1と同じで反復処理などがある場合は
Numbaが高速化されます
コツ3.大量の繰り返し計算によるシミュレーション(モンテカルロ法)
最後に大量の繰り返し計算を行う場合の
シミュレーション(モンテカルロ法)を比較してみます
今回の例では大量の計算を繰り返して
円周率(π)の近似値を求めてみます
円周率(π)を近似計算してみるよ
Numpyによる実装
import numpy as np
import time
# 試行回数
num_samples = 1000000 # 100万回の試行
# モンテカルロ法でπを計算
%%timeit
x = np.random.rand(num_samples) # ランダムなx座標を生成
y = np.random.rand(num_samples) # ランダムなy座標を生成
inside_circle = np.sum(x**2 + y**2 <= 1.0) # 原点からの距離が1以下の点を数える
pi_estimate = 4 * inside_circle / num_samples # πの近似値を計算
# 計算結果
pi_estimate: 3.140288
# 処理時間
56.4 ms ± 10.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Numbaによる実装
from numba import jit
import numpy as np
import time
# 試行回数
num_samples = 1000000 # 100万回の試行
# JITコンパイルを適用したモンテカルロ法によるπの計算
@jit(nopython=True)
def monte_carlo_pi(num_samples):
inside_circle = 0
for _ in range(num_samples):
x = np.random.rand() # ランダムなx座標を生成
y = np.random.rand() # ランダムなy座標を生成
if x**2 + y**2 <= 1.0:
inside_circle += 1 # 原点からの距離が1以下の点をカウント
return 4 * inside_circle / num_samples # πの近似値を返す
# Numbaでモンテカルロ法を実行
%%timeit
pi_estimate = monte_carlo_pi(num_samples) # JITコンパイルされた関数を実行
pi_estimate
# 計算結果
pi_estimate: 3.142132
# 処理時間
21.8 ms ± 5.69 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
処理速度は以下のとおりでした
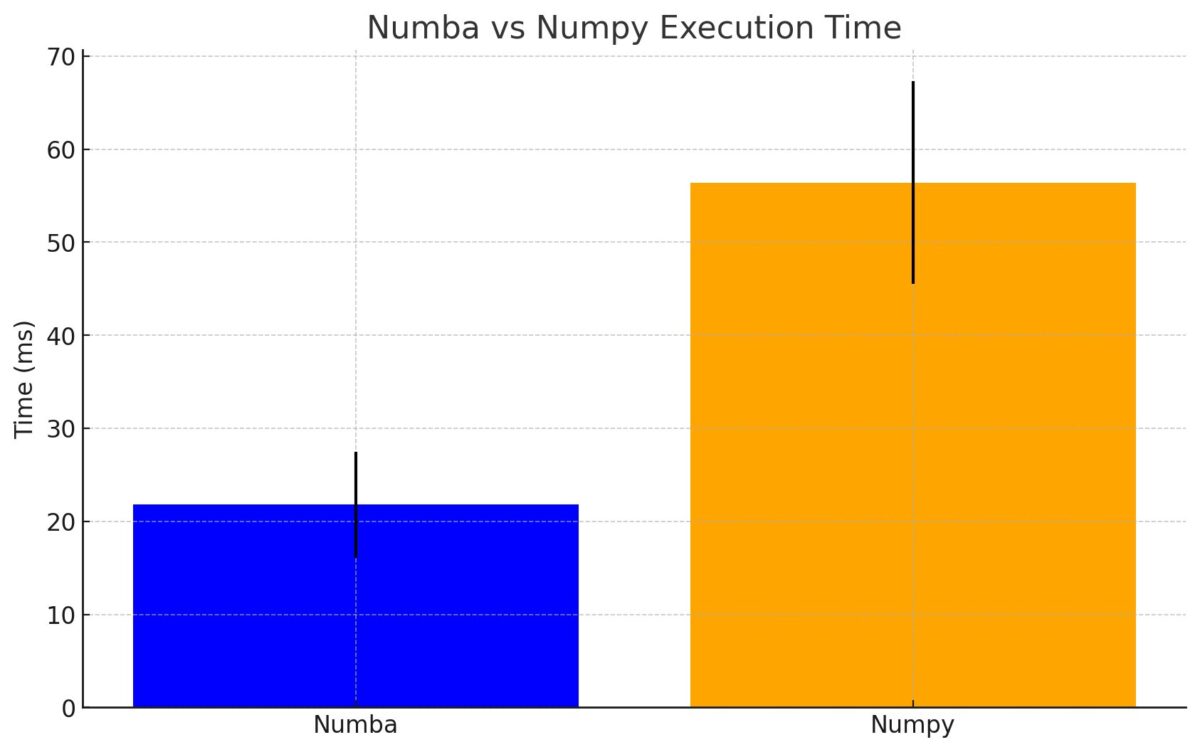
Numbaの方が3倍程度速い結果となりました
Numpyはベクトル化された操作は高速ですが
多数の反復処理(for, if)の場合がある場合は
やはりNumbaに軍配があがります
Numbaでできないことや注意点
Numbaは高速化に強力ですが、万能ではありません
以下にできないことや注意点をまとめます
Numbaのできないこと・・・
- サポートされない機能:文字列操作,一部のライブラリはサポート外
- エラーハンドリングの制約:try, except のような例外処理は組み込めない(エラーになる)
これらの制約の対応策としては
nopython モードを無効にしたり
例外処理の部分はNumbaの外に出すなどの対応が必要です
たとえば以下のような例外処理を入れたコードを実行してもエラーが発生します
jitの中に例外処理を含むコード(エラー発生)
from numba import jit
@jit(nopython=True)
def divide_numbers(x, y):
try:
return x / y
except ZeroDivisionError:
return "Cannot divide by zero"
# この関数を実行すると、Numbaがサポートしていない例外処理が含まれているためエラーが発生します
result = divide_numbers(10, 0)
No implementation of function Function(
Numbaの特徴を理解して、適切な場面で有効活用して
高速化を一緒にがんばっていきましょう!!
