

Pythonを使ってデータ分析を始めようと思っている方へ
本記事ではデータ分析の基本から
たくさんのデータを効率的に処理する方法を紹介します
この記事が役に立つ方は以下のとおり
- データ分析をPythonで初めて行う方
- Pandasの基本的な使い方を知りたい方
- 簡単な数値計算やデータ処理を学びたい方
dataframeの欠損値についての確認方法などを
詳しく知りたい場合は
以下の記事で解説しているので参考にしてみてください
Pandasの基本機能とDataFrameの概要
まず、Pandasの基本的な役割について簡単に説明します
Pandasは、データの操作や解析を容易にするためのツールです
以下にPandasの基本機能とDataFrameの概要を簡潔にまとめます
- データの読み込み:CSV、Excel、SQLなどのデータソースからデータを読み込む
- データの操作:データのフィルタリング、並び替え、集計などを行う
- データの出力:加工したデータをファイルに書き出す
二次元データでエクセルの表みたいな見た目だよー
Pandasを使えば、
大量のデータを簡単に整理し
必要な情報をすばやく抽出できます
DataFrameの作成と操作方法(列選択、追加、削除)
dataframeの作成方法と
基礎的な操作方法を解説します
DataFrameの作成方法
DataFrameは、リスト、辞書あるいはNumPy配列などの
さまざまなデータから作成することができます
以下にリストと辞書を使ったDataFrameの作成例を示します
import pandas as pd
# リストを使用してDataFrameを作成
data = [['田中', 23, 'エンジニア'], ['鈴木', 45, 'デザイナー'], ['佐藤', 36, 'データサイエンティスト']]
df_list = pd.DataFrame(data, columns=['名前', '年齢', '職業'])
# 辞書を使用してDataFrameを作成
data_dict = {'名前': ['田中', '鈴木', '佐藤'], '年齢': [23, 45, 36], '職業': ['エンジニア', 'デザイナー', 'データサイエンティスト']}
df_dict = pd.DataFrame(data_dict)
# DataFrameの表示
print(df_list)
print(df_dict)
# 出力結果:(df_list, df_dictも同じ出力結果)
#
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 1 鈴木 45 デザイナー
# 2 佐藤 36 データサイエンティスト
listの場合はcolumnsを使用することで
列名を指定することができます
列や行の選択、追加、削除方法
次に、DataFrameから特定の列や行を選択
追加、削除する方法を説明します
# サンプルデータ
# df_list
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 1 鈴木 45 デザイナー
# 2 佐藤 36 データサイエンティスト
# 列の選択(特定の列を選択)///////////////////////////////////////////
names = df_list['名前']
print(names)
# 出力結果:
# 0 田中
# 1 鈴木
# 2 佐藤
# Name: 名前, dtype: object
# 行の選択(行番号を指定)///////////////////////////////////////////
row_1 = df_list.iloc[1] # 1行目を選択
print(row_1)
# 出力結果:
# 名前 鈴木
# 年齢 45
# 職業 デザイナー
# Name: 1, dtype: object
# 列や行の追加////////////////////////////////////////////////////
df_list['国籍'] = ['日本', '日本', '日本']
print(df_list)
# 出力結果:
# 名前 年齢 職業 国籍
# 0 田中 23 エンジニア 日本
# 1 鈴木 45 デザイナー 日本
# 2 佐藤 36 データサイエンティスト 日本
# 新しい行を追加///////////////////////////////////////////////
new_row = pd.DataFrame([['山田', 30, 'プロダクトマネージャー', '日本']], columns=df_list.columns)
df_list = pd.concat([df_list, new_row], ignore_index=True)
print(df_list)
# 出力結果:
# 名前 年齢 職業 国籍
# 0 田中 23 エンジニア 日本
# 1 鈴木 45 デザイナー 日本
# 2 佐藤 36 データサイエンティスト 日本
# 3 山田 30 プロダクトマネージャー 日本
# 列や行の削除////////////////////////////////////////////////////
# 列の削除
df_list = df_list.drop('国籍', axis=1)
print(df_list)
# 出力結果:
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 1 鈴木 45 デザイナー
# 2 佐藤 36 データサイエンティスト
# 3 山田 30 プロダクトマネージャー
# 行の削除
df_list = df_list.drop(2, axis=0)
print(df_list)
# 出力結果:
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 1 鈴木 45 デザイナー
# 3 山田 30 プロダクトマネージャー
文字列の場合はlocメソッドを使用してね
このように、Pandasでは簡単に
列や行を操作することができ
柔軟にデータを加工することができます
データのフィルタリングや並び替え(sort_values)
データ分析の際には、特定の条件に基づいて
データをフィルタリングしたり
並び替えを行うことがあります
以下にフィルタリングと並び替えの例を示します
# データのフィルタリング////////////////////////////////////////
# 年齢が30以上の行をフィルタリング
filtered_df = df_list[df_list['年齢'] >= 30]
print(filtered_df)
# 出力結果:
# 名前 年齢 職業
# 1 鈴木 45 デザイナー
# 3 山田 30 プロダクトマネージャー
# データの並び替え////////////////////////////////////////////
# 年齢で昇順に並び替え
sorted_df = df_list.sort_values('年齢')
print(sorted_df)
# 出力結果:
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 3 山田 30 プロダクトマネージャー
# 1 鈴木 45 デザイナー
sort_valuesの引数には以下のような種類があります
それぞれの意味と使い方を簡単にまとめておきます
sort_valuesの引数一覧
- sort_valuesの引数一覧が知りたい方はこちらをクリック
by
説明: ソートの基準とする列または列のリスト(必須引数)
使用例: df.sort_values(by=’column_name’)
axis
説明: ソートする軸を指定します。
0はインデックス(行)で、1は列ですデフォルトは0(行方向)
使用例: df.sort_values(by=’column_name’, axis=0)
ascending
説明: ソート順を指定するブール値
Trueで昇順、Falseで降順
リストで指定すると複数の列に対して個別のソート順を設定できます
デフォルトはTrue
使用例: df.sort_values(by=’column_name’, ascending=False)
inplace
説明: 元のデータフレームをソートされた状態に
更新するかどうかを指定するブール値
Trueにすると、元のデータフレームが変更されます
デフォルトはFalse
使用例: df.sort_values(by=’column_name’, inplace=True)
kind
説明: ソートアルゴリズムを指定します
‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’ の4つから選べます
デフォルトは’quicksort’
使用例: df.sort_values(by=’column_name’, kind=’mergesort’)
na_position
説明: 欠損値(NaN)の位置を指定します
‘first’(先頭)または’last’(末尾)を指定できます
デフォルトは’last’
使用例: df.sort_values(by=’column_name’, na_position=’first’)
ignore_index
説明: ソート後にインデックスをリセットするかどうかを
指定するブール値Trueにすると、インデックスが0から始まる連続した整数になります
デフォルトはFalse
使用例: df.sort_values(by=’column_name’, ignore_index=True)
key
説明: ソート前に列の値に適用する関数を指定します
各要素に対して関数が適用され、その結果がソートされます
使用例: df.sort_values(by=’column_name’, key=lambda x: x.str.lower())
数値計算の基本操作(演算、グループ化、欠損値の処理)
次に数値計算の基本操作について説明します
ここでは以下の項目について例を示します
- 基本的な数値演算
- 列ごとの集計やグループ化
- 欠損値の処理方法
基本的な数値演算の方法
加算、減算、乗算、除算などの基本的な演算は、以下のとおりです
import pandas as pd
# サンプルデータ
data = {'名前': ['田中', '鈴木', '佐藤'], '年齢': [23, 45, 36], '年収': [500, 800, 600]}
df = pd.DataFrame(data)
# df
# 名前 年齢 職業
# 0 田中 23 エンジニア
# 3 山田 30 プロダクトマネージャー
# 1 鈴木 45 デザイナー
# 基本的な数値演算の例////////////////////////////////////////
# 年収を1.1倍する(例: 昇給率10%)
df['昇給後年収'] = df['年収'] * 1.1
# 新しい列「年収+年齢」を作成
df['年収+年齢'] = df['年収'] + df['年齢']
print(df)
# 出力結果:
# コードをコピーする
# 名前 年齢 年収 昇給後年収 年収+年齢
# 0 田中 23 500 550.0 523
# 1 鈴木 45 800 880.0 845
# 2 佐藤 36 600 660.0 636
この例では、「年収」を1.1倍にした「昇給後年収」列を追加し
「年収」と「年齢」を合計した列を作成しています
列ごとの集計(グループ化)
特定の列に対してグループ化を行うことで
狙ったデータのみの集計を行うことができます
groupbyメソッドを使って簡単に実行できます
import pandas as pd
# サンプルデータ(新しい列「部署」を追加)
df['部署'] = ['営業', '開発', '営業']
# df
# 名前 年齢 年収 部署
# 0 田中 23 500 営業
# 1 鈴木 45 800 開発
# 2 佐藤 36 600 営業
# 列ごとの集計とグループ化の例////////////////////////////////////////
# 部署ごとの平均年収を計算
grouped = df.groupby('部署')['年収'].mean()
print(grouped)
# 出力結果:
# 部署
# 営業 550.0
# 開発 800.0
# Name: 年収, dtype: float64
この例では、部署ごとの平均年収を計算しています
groupbyを使うことで、指定した列などをめとめた
集計を効率的に行えます
欠損値の処理方法
現実のデータセットでは、しばしば欠損値(NaN)が存在します
Pandasは欠損値の除去や、特定の値での補完などが簡単に行えます
import pandas as pd
# サンプルデータ(欠損値を含める)
data_with_nan = {'名前': ['田中', '鈴木', '佐藤'], '年齢': [23, None, 36], '年収': [500, 800, None]}
df_nan = pd.DataFrame(data_with_nan)
# df_nan
# 名前 年齢 年収
# 0 田中 23.0 500.0
# 1 鈴木 NaN 800.0
# 2 佐藤 36.0 NaN
# 欠損値の処理方法////////////////////////////////////////
# 欠損値を0で補完
df_filled = df_nan.fillna(0)
print(df_filled)
# 出力結果:
# 名前 年齢 年収
# 0 田中 23.0 500.0
# 1 鈴木 NaN 800.0
# 2 佐藤 36.0 NaN
# 欠損値を含む行を削除////////////////////////////////////////
df_dropped = df_nan.dropna()
print(df_dropped)
# 出力結果:
# 名前 年齢 年収
# 0 田中 23.0 500.0
この例では、欠損値を0で補完する方法と
欠損値を含む行を削除する方法を示しています
もっと詳しい欠損値の確認方法については以下の記事で
解説しているので参考にしてみてください
統計分析とデータの可視化
データを、グラフで視覚的に確認することは
全体のデータ傾向を判断する上で重要です
ここでは以下の項目について例を示します
- 基本的な統計分析の方法
- MatplotlibやSeabornを使ったデータの可視化
- 実際のデータを用いた分析事例
基本的な統計分析
今回は平均、中央値、分散、標準偏差などを計算します
import pandas as pd
# サンプルデータ
data = {'名前': ['田中', '鈴木', '佐藤', '山田', '高橋'], '年齢': [23, 45, 36, 29, 50], '年収': [500, 800, 600, 400, 700]}
df = pd.DataFrame(data)
# df
# 名前 年齢 年収
# 0 田中 23 500
# 1 鈴木 45 800
# 2 佐藤 36 600
# 3 山田 29 400
# 4 高橋 50 700
# 基本的な統計分析////////////////////////////////////////
# 平均値を計算
mean_age = df['年齢'].mean()
mean_income = df['年収'].mean()
# 中央値を計算
median_age = df['年齢'].median()
median_income = df['年収'].median()
# 分散と標準偏差を計算
variance_age = df['年齢'].var()
std_income = df['年収'].std()
# 統計量の表示
print(f"年齢の平均: {mean_age}, 中央値: {median_age}, 分散: {variance_age}")
print(f"年収の平均: {mean_income}, 中央値: {median_income}, 標準偏差: {std_income}")
# 出力結果:
# 年齢の平均: 36.6, 中央値: 36.0, 分散: 134.3
# 年収の平均: 600.0, 中央値: 600.0, 標準偏差: 158.11
この例では、年齢と年収の平均、中央値
分散、標準偏差を計算しています
これらの統計量を把握することで
データの傾向やばらつきを把握することができます
MatplotlibやSeabornを使ったデータの可視化
データを視覚的に表現することで
パターンやトレンドをより直感的に理解できます
# サンプルデータ
data = {'名前': ['田中', '鈴木', '佐藤', '山田', '高橋'], '年齢': [23, 45, 36, 29, 50], '年収': [500, 800, 600, 400, 700]}
df = pd.DataFrame(data)
# df
# 名前 年齢 年収
# 0 田中 23 500
# 1 鈴木 45 800
# 2 佐藤 36 600
# 3 山田 29 400
# 4 高橋 50 700
# Matplotlibを使ったデータの可視化/////////////////////////////////
import matplotlib.pyplot as plt
# 年齢のヒストグラムを作成
plt.hist(df['年齢'], bins=5, color='skyblue')
plt.title('income graph')
plt.xlabel('age')
plt.ylabel('humans')
plt.show()
# Seabornを使ったデータの可視化///////////////////////////////////
import seaborn as sns
# 年収と年齢の関係を示す散布図を作成
sns.scatterplot(x='年齢', y='年収', data=df, color='blue')
plt.title('Relationship between annual income and age')
plt.xlabel('age')
plt.ylabel('income')
plt.show()
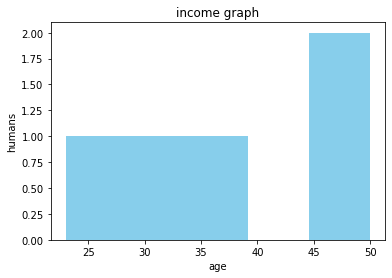
上記のコードで以下のようなグラフを表示することができます
ヒストグラム
散布図
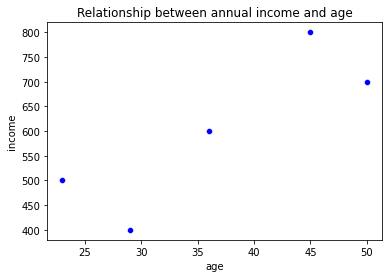
今回作成したグラフからわかることは以下のとおりです
- ヒストグラム: 年齢の分布が棒グラフとして表示され、どの年齢層が多いかが一目でわかります
- 散布図: 年齢と年収の関係が点でプロットされ、相関関係を視覚的に確認できます
Pandasを使った応用的なデータ分析(結合、時系列データ、ピポットテーブル)
ここでは以下の点について説明します
- 複数のDataFrameの結合(merge, concat)
- 時系列データの作成・リサンプリング
- ピポットテーブルの作成
DataFrameの結合(merge)
ここではmergeの方法について説明します
import pandas as pd
# サンプルデータ
df1 = pd.DataFrame({'社員ID': [1, 2, 3], '名前': ['田中', '鈴木', '佐藤']})
df2 = pd.DataFrame({'社員ID': [1, 2, 4], '部署': ['営業', '開発', '人事']})
# df1
# 社員ID 名前
# 0 1 田中
# 1 2 鈴木
# 2 3 佐藤
# df2
# 社員ID 部署
# 0 1 営業
# 1 2 開発
# 2 4 人事
# DataFrameのマージ/////////////////////////////////////////
# 社員IDをキーにしてマージ
merged_df = pd.merge(df1, df2, on='社員ID', how='inner')
print(merged_df)
# 出力結果:
# 社員ID 名前 部署
# 0 1 田中 営業
# 1 2 鈴木 開発
この例では、社員IDをキーとして
2つのDataFrameを結合しています
how=’inner’は共通するキーを
持つ行だけをマージする設定です
merge関数にはたくさんの引数があります
各引数を簡単に紹介しておきます
merge関数の引数一覧
- mergeの引数一覧が知りたい方はこちらをクリック
right
説明: 結合する2つ目のデータフレーム
使用例: df1.merge(df2, on=’key’)
how
説明: 結合方法を指定する
オプション:
inner: 両方のデータフレームに共通するキーのみを保持
outer: 両方のデータフレームにあるすべてのキーを保持
left: 左側のデータフレームのすべてのキーを保持
right: 右側のデータフレームのすべてのキーを保持
使用例: df1.merge(df2, how=’outer’, on=’key’)
on
説明: 結合に使用する列名またはインデックスの名前を指定する
使用例: df1.merge(df2, on=’key’)
left_on
説明: 左側のデータフレームの結合に使用する
列名またはインデックスの名前を指定する
使用例: df1.merge(df2, left_on=’key1′, right_on=’key2′)
right_on
説明: 右側のデータフレームの結合に使用する
列名またはインデックスの名前を指定する
使用例: df1.merge(df2, left_on=’key1′, right_on=’key2′)
left_index
説明: 左側のデータフレームのインデックスを
結合に使用するかどうかを指定する(True または False)
使用例: df1.merge(df2, left_index=True, right_on=’key’)
right_index
説明: 右側のデータフレームのインデックスを
結合に使用するかどうかを指定する(True または False)
使用例: df1.merge(df2, left_on=’key’, right_index=True)
sort
説明: 結合結果をキーでソートするかどうかを指定する(True または False)
使用例: df1.merge(df2, on=’key’, sort=True)
suffixes
説明: 共通の列名に対する接尾辞を指定する(デフォルトは (‘_x’, ‘_y’))
使用例: df1.merge(df2, on=’key’, suffixes=(‘_left’, ‘_right’))
copy
説明: 結合されたデータフレームが
コピーされるかどうかを指定する(True または False)
使用例: df1.merge(df2, on=’key’, copy=False)
indicator
説明: 結合結果にどのデータフレームから行が
来たのかを示す列を追加するかどうかを指定する
True または列名(文字列)を指定すると新しい列が追加される
使用例: df1.merge(df2, on=’key’, indicator=True)
validate
説明: 結合の方法をチェックするためのオプションで
データの一貫性を確認する
one_to_one, one_to_many, many_to_one, many_to_many から選択
使用例: df1.merge(df2, on=’key’, validate=’one_to_many’)
DataFrameの結合(concat)
ここではconcatの方法について説明します
import pandas as pd
# サンプルデータ(結合するためのデータを作成)
df3 = pd.DataFrame({'社員ID': [5, 6], '名前': ['山田', '高橋']})
# df1
# 社員ID 名前
# 0 1 田中
# 1 2 鈴木
# 2 3 佐藤
# df3
# 社員ID 名前
# 0 5 山田
# 1 6 高橋
# DataFrameを縦に結合////////////////////////////////////////
concat_df = pd.concat([df1, df3], ignore_index=True)
print(concat_df)
# 出力結果:
# 社員ID 名前
# 0 1 田中
# 1 2 鈴木
# 2 3 佐藤
# 3 5 山田
# 4 6 高橋
この例では、2つのDataFrameを縦(行方向)に結合しています
新しいDataFrameのインデックスが再割り当てされるよ
concat関数にはたくさんの引数があります
今回はそれらを簡単に紹介しておきます
concatの引数一覧
- concatの引数一覧が知りたい方はこちらをクリック
objs
結合するオブジェクト(リストまたは辞書)必須引数
例: pd.concat([df1, df2])
axis
結合する軸を指定
0(デフォルト):行方向に結合(縦方向)
1:列方向に結合(横方向)
例: pd.concat([df1, df2], axis=1)
join
結合方法を指定
‘outer’(デフォルト):すべてのインデックスを保持(外部結合)
‘inner’:共通のインデックスのみ保持(内部結合)
例: pd.concat([df1, df2], join=’inner’)
ignore_index
インデックスを無視してリセットするかどうかを指定
False(デフォルト):元のインデックスを保持
True:新しい連続したインデックスを割り当てる
例: pd.concat([df1, df2], ignore_index=True)
keys
結合された各データフレームやシリーズに
新しいマルチインデックスを割り当てるためのキーを指定
例: pd.concat([df1, df2], keys=[‘A’, ‘B’])
levels
keys を指定した場合に、マルチインデックスのレベルを明示的に指定
例: pd.concat([df1, df2], keys=[‘A’, ‘B’], levels=[[‘A’, ‘B’, ‘C’]])
names
マルチインデックスの名前を指定
例: pd.concat([df1, df2], keys=[‘A’, ‘B’], names=[‘Group’])
verify_integrity
結合後に重複したインデックスが存在する場合にエラーを発生させるかどうかを指定
False(デフォルト):重複を許可
True:重複があるとエラーを発生させる
例: pd.concat([df1, df2], verify_integrity=True)
sort
結合時に軸をソートするかどうかを指定
False(デフォルト):ソートしない
True:軸をソートする
例: pd.concat([df1, df2], sort=True)
copy
結合する際にデータをコピーするかどうかを指定
True(デフォルト):データをコピー
False:データを直接使用(場合によってはメモリ効率が良くなる)
例: pd.concat([df1, df2], copy=False)
時系列データの作成とリサンプリング
Pandasには、時系列データを
扱うための機能が豊富に用意されているので紹介します
時系列データの作成
まずは時系列データを作成する方法を紹介します
import pandas as pd
# サンプルデータ
dates = pd.date_range('2023-01-01', periods=6, freq='D') # 日付の範囲を生成
df_ts = pd.DataFrame({'日付': dates, '売上': [100, 150, 200, 250, 300, 350]})
df_ts.set_index('日付', inplace=True) # 日付をインデックスに設定
# df_ts
# 売上
# 日付
# 2023-01-01 100
# 2023-01-02 150
# 2023-01-03 200
# 2023-01-04 250
# 2023-01-05 300
# 2023-01-06 350
# 時系列データの基本操作の例////////////////////////////////////////
# 特定期間のデータを抽出
subset = df_ts['2023-01-02':'2023-01-04']
print(subset)
# 出力結果:
# 売上
# 日付
# 2023-01-02 150
# 2023-01-03 200
# 2023-01-04 250
この例では、日付をインデックスにしたDataFrameを作成し
特定の期間のデータを抽出しています
data_range関数にはたくさんの引数があります
今回はそれらを簡単に紹介しておきます
data_range関数の引数一覧
- data_rangeの引数一覧が知りたい方はこちらをクリック
start
生成する日付範囲の開始日を指定
文字列または Timestamp オブジェクト
例: pd.date_range(start=’2023-01-01′, end=’2023-01-10′)
end
生成する日付範囲の終了日を指定
文字列または Timestamp オブジェクト
例: pd.date_range(start=’2023-01-01′, end=’2023-01-10′)
periods
生成する日付の数を指定
start または end と一緒に使うか、どちらも指定しない場合に使用
例: pd.date_range(start=’2023-01-01′, periods=10)
freq
日付範囲を生成する頻度を指定
例: ‘D’(デフォルト、日単位)、’H’(時間単位)、’M’(月単位)など
例: pd.date_range(start=’2023-01-01′, periods=10, freq=’M’)
tz
生成される日付にタイムゾーンを指定
例: ‘UTC’, ‘Asia/Tokyo’ など
例: pd.date_range(start=’2023-01-01′, periods=10, tz=’Asia/Tokyo’)
normalize
すべての日付を深夜(午前0時)に正規化するかどうかを指定
False(デフォルト):日付はそのまま
True:日付が深夜に正規化される
例: pd.date_range(start=’2023-01-01 14:00′, periods=3, normalize=True)
name
生成された DatetimeIndex に名前を付ける
例: pd.date_range(start=’2023-01-01′, periods=10, name=’my_dates’)
closed
範囲の閉じ方を指定
None(デフォルト):開始日と終了日が含まれる
‘left’:開始日を含むが、終了日は含まない
‘right’:終了日を含むが、開始日は含まない
例: pd.date_range(start=’2023-01-01′, end=’2023-01-10′, closed=’right’)
inclusive (Pandas 1.4.0以降)
範囲の包含を指定
‘both’(デフォルト):開始日と終了日を含む
‘neither’:どちらも含まない
‘left’:開始日を含むが、終了日は含まない
‘right’:終了日を含むが、開始日は含まない
例: pd.date_range(start=’2023-01-01′, end=’2023-01-10′, inclusive=’left’)
kwargs
他のキーワード引数を指定可能
例: pd.date_range(start=’2023-01-01′, periods=10, freq=’D’, inclusive=’left’)
時系列データのリサンプリング
次に時系列データのリサンプリングの例を紹介します
import pandas as pd
# サンプルデータ
# df_ts
# 売上
# 日付
# 2023-01-01 100
# 2023-01-02 150
# 2023-01-03 200
# 2023-01-04 250
# 2023-01-05 300
# 2023-01-06 350
# 時系列データのリサンプリングの例////////////////////////
# デイリーのデータを月次の合計にリサンプリング
monthly_sales = df_ts.resample('M').sum() # 'M'は月を意味
print(monthly_sales)
# 出力結果:
# 日付
# 2023-01-31 1350
この例では、日毎の売上データを
月毎の合計にリサンプリングしています
resample関数にはたくさんの引数があります
今回はそれらを簡単に紹介しておきます
resample の引数一覧
- resampleの引数一覧が知りたい方はこちらをクリック
rule
再サンプリングする頻度を指定
例: ‘D’(日単位)、’M’(月単位)、’H’(時間単位)など
例: df.resample(‘M’).mean()
axis
再サンプリングする軸を指定
デフォルトは 0(行軸)
例: df.resample(‘M’, axis=1).mean()
closed
リサンプリングのバケットを閉じる側を指定
‘right’(デフォルト):右端を含む
‘left’:左端を含む
例: df.resample(‘D’, closed=’left’).sum()
label
再サンプリング後のラベルをどちらに配置するかを指定
‘right’(デフォルト):右端のラベルを使用
‘left’:左端のラベルを使用
例: df.resample(‘D’, label=’left’).sum()
convention
四半期のリサンプリング時に、’start’ または ‘end’ を指定して開始または終了を決定
デフォルトは ‘start’
例: df.resample(‘Q’, convention=’end’).sum()
kind
出力するインデックスの型を指定
‘timestamp’(デフォルト):タイムスタンプ
‘period’:期間
例: df.resample(‘M’, kind=’period’).sum()
loffset (廃止予定: 1.1.0)
各バケットのラベルをシフトするために使用
使用する場合は、shift メソッドを代わりに利用します
例: df.resample(‘D’).mean().shift(freq=’1H’)
base (廃止予定: 1.1.0)
新しい時間系列の開始点を指定(秒、分、時間などのオフセット)
例: df.resample(’15T’, base=5).mean()
offset 引数を使用して、代替方法を使用します
on
リサンプリングに使用する列を指定DataFrame の場合にのみ使用
例: df.resample(‘M’, on=’date’).sum()
level
マルチインデックスのレベルを指定してリサンプリング
例: df.resample(‘M’, level=’date_level’).sum()
origin (Pandas 1.1.0以降)
バケットの開始点を指定
‘epoch’(デフォルト):エポック(1970-01-01 00:00:00)から
‘start’:データの最初のタイムスタンプから
‘start_day’:データの最初のタイムスタンプの最初の時間から
例: df.resample(‘D’, origin=’start_day’).mean()
offset (Pandas 1.1.0以降)
各バケットの開始をオフセット
例: df.resample(‘M’, offset=’1D’).mean()
group_keys
グループ化された結果のラベルを保持するかどうかを指定
デフォルトは True
例: df.resample(‘M’, group_keys=True).apply(lambda x: x.sum())
ピポットテーブルの作成
最後に、ピボットテーブルの作成方法について解説します
import pandas as pd
# サンプルデータ
df_pivot = pd.DataFrame({
'日付': ['2023-01-01', '2023-01-02', '2023-01-01', '2023-01-02'],
'商品': ['A', 'A', 'B', 'B'],
'売上': [100, 150, 200, 250]
})
# df_pivot
# 日付 商品 売上
# 0 2023-01-01 A 100
# 1 2023-01-02 A 150
# 2 2023-01-01 B 200
# 3 2023-01-02 B 250
# データのピボットの例////////////////////////
# ピボットテーブルを作成
pivot_table = df_pivot.pivot(index='日付', columns='商品', values='売上')
print(pivot_table)
# 出力結果:
# 商品 A B
# 日付
# 2023-01-01 100.0 200.0
# 2023-01-02 150.0 250.0
pivot の引数一覧
- index: 行ラベルとして使用する列または列のリスト
- columns: 列ラベルとして使用する列または列のリスト
- values: テーブルに表示する値として使用する列
この例では、データを商品別に日付ごとに
集計したピボットテーブルを作成しています
これにより、複数の商品やカテゴリを分析する際に
非常に見やすい形にデータを整理できます
Pandasを使ったデータ分析の基本は理解できたでしょうか?
結合や時系列データの扱い、さらにデータの変形とリサンプリングを
駆使することで、より複雑なデータ分析が可能になります
これからもいろんなテクニックを紹介していくので
一緒にさらっとデータ分析をしてモテるエンジニアを目指しましょう!笑
